False assumptions in distributed computing happen all the time, and they often have high costs. Peter Deutsch asserts that there are at least 7 false assumptions system architects and software developers are likely to make, and James Gosling later added an eighth fallacy.
- The network is reliable
- Latency is zero
- Bandwidth is infinite
- The network is secure
- Topology doesn’t change
- There is one administrator
- Transport cost is zero
- The network is homogeneous
We’ll look through each one, why it’s relevant when designing and operating any distributed application, and explain what you should genuinely assume (the worst).
1. The Network is Reliable
No. The network is NOT reliable. Developers and users get to live in a beautiful abstract world where the possibility of things going wrong that they’re on the hook for is complicated but quite bounded. The ops team is out there running a bunch of metal, sand, and silicon zipping and zapping your abstracted messages across the country/globe. This is the real world; stuff is bound to go wrong and to be quite honest, it’s amazing any of this even works at all! Cables are bound to be tripped on, dug up by accident with a backhoe, or otherwise get damaged. Hardware can fail with no prior indication that it’s about to fail. Administrative mistakes are bound to happen. Everyday changes to the configuration of this extensive, multilayered system we call the network are going to go sideways eventually. It gets even crazier if we zoom in to a small timescale as networks have micro-failures and inconsistencies all the time! Switch buffers may fill, packets get dropped, changes in latency over brief periods (jitter) can occur, each of these possibly many times each day with potentially devasting impact on the performance of an application.

Applications must be designed to account for these types of issues. If an outage occurs, should the application stall? When the network comes back, does it attempt to reconnect gracefully or does it require a manual restart? How does your application handle lost messages? Does it keep trying to send them out every few milliseconds, flooding the network? These are all questions you should be asking yourself as you plan your error handling.

Network issues can potentially be a large portion of the set of negative experiences users have with your application. You need to assume that sometimes, there is no network. Pretend you’re connected at random times throughout the day, but not at all times. If your application relies on reliable connectivity to perform its goals, think about how it’s communicating this failure to the users/ops team. Put some thought into this, and provide the user with the least frustrating experience you can, and your application will be robust.
2. Latency is Zero
A network can be described as a series of queues (routers/switches), each connected to one other (with cables). It takes time to both sit in each queue. It also takes time to travel out one queue and into the next one (bounded by the speed of light). The time it takes sitting in a queue is referred to as queueing delay. The time it takes to travel from one queue to another is called propagation delay.
Latency is all the queue, and propagation delays (and a few other, but lower order types of delays) between the transmitter and receiver added together - and doing the math, it’s impossible for this to be zero. Using traditional and widespread methods, information can only travel so fast, and unless you’re developing for a quantum network, you must assume latency is present for each message you send. The network is a tool to aid in distributing your application, but it should not be abused.

As you can see, network latency is orders of magnitude higher than local memory. Each scenario is a little different, but the picture that needs to be painted in your head is that they are not even in the same class of storage by a longshot. Each node in your system is its own discrete unit of compute and treating a remote node like it’s local memory will end in disappointment when scaling up. What’s worse is if you don’t design around chaotic or high latency, your application may work fine on your LAN test network but fail miserably when deployed over a WAN/internet connection.

With distributed systems and microservices, it’s easy to get swept up into the convenience of relying on services that may need to call other services (which maybe you don’t think about it further, but it keeps going). Try to be mindful of how many levels of calls will be made under the conditions of which your application operates.
In some scenarios, you can also reduce the impact of latency by pulling in more data than you will definitely need, including some data that you might need. This potentially reduces the need for multiple future back-and-forth messaging. Going too far with this, however, leads us to the next fallacy.
3. Bandwidth is Infinite
Bandwidth is the amount of data that can be transmitted or received at any given time. It makes no guarantee of how long it takes for that data to be received, that’s what latency is. Like CPU cycles, memory, and storage, bandwidth is a resource and abusing that resource can result in bottlenecks. Additionally, bandwidth utilized correlates with increases in latency once a specific lower bound has been reached.
As mentioned at the end of fallacy #2, you should pull in data that you might need, but within reason. Fallacy #2 and #3 are a balancing act and where you end up on the line between them is different for each application - but they both exist as fallacies in this list because you must not forget either one.
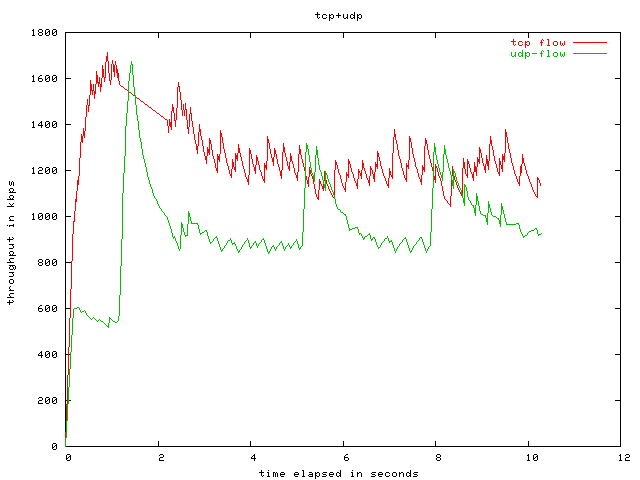
There are certain aspects of the network that your operations team may be able to tune for you, such as configuring different priority queues on all the forwarding devices throughout the network. It’s up to you to identify the types of traffic that should be prioritized and ensure operations has implemented separate queues for it. A typical example is voice traffic (eg, skype, google hangouts, mumble, Ventrilo, discord, etc.) which is low bandwidth but must be delivered in as close to real-time as possible, so it’s put in a highegr priority queue than most other traffic.
Let me tell you about a complete failure due to disregarding bandwidth. I had a $140 overage on my cell phone bill last month because I decided to tether my laptop to it because I had to perform some work and had no other means of getting connected. There was an application which will not be named that was continually transmitting data to a server that was pretty much several MB of duplicate data about the machine every few moments. That is an example of a horribly written application. For distributed systems, it gets more complicated, because often times data has to transit from one service to another, possibly up to more services later on, etc. Remember, that the network is a shared resource, and each time the data has to transit the network, it’s using up that time where no other services can be transmitted on the same link.
4. The Network is Secure
The day we started connecting different computers together was the day that all hopes of security went out of window.
Making the assumption that the network is secure is similar to making the assumption seatbelts aren’t required since driving is safe (hint, it’s not!). Security practitioners will always recommend defense in depth, and each layer in the stack should be implemented with a security-first mindset.
Security considerations should be especially considered when implementing distributed systems. Often times, these systems are handling unrelated workloads. If you’re negligent to security, you might find that information is being sent out in the clear. If there’s a malicious service operating in your cluster, should it really be able to see all the information being passed between nodes?
Okay now, let’s talk about everything that’s out of your control. Listen, it gets pretty rough here, but the fact is you simply have to accept the risk and how it will impact you, and prepare for it. It’s not a matter of if you’ll be compromised at some point, it’s a matter of when. It’s tough to accept, but it’s the attitude you must maintain as you go about developing your application and other things in life. The fact of the matter is, I think that we, as intelligent beings, have gotten a little bit ahead of ourselves in implementing the technology we’ve discovered/invented. We’ve applied too much before fully understanding it.

5. Topology Doesn’t Change
Infrastructure topology should be decoupled from how your application works, when possible. Topology changes happen all the time, and if your application easily breaks for standard changes, then you likely haven’t built an excellent app. Do not hard code IP addresses. Do not treat your servers or infrastructure as loving pets - they are cattle. With cloud services springing up everywhere, and everyone moving to them - you can bet that topologies will only change at a faster rate than ever before.
There are many reasons we may have different topologies. We may have an MPLS link to connect up our line of business applications to service users in other sites, and we may also have a standard IPsec tunnel between sites that utilizes the respective sites internet connection. While the MPLS link will have better properties for our application than our shared-with-everyone-in-the-world internet connection, your operations team has likely configured the network to failover to the IP Sec tunnel if the MPLS goes offline for any reason. Uptime is prioritized over static conditions, and your application is expected to adapt to these changes - because a lot of work is put into keeping the network up over keeping the network static. Routing protocols are continually changing the topology of the system due to the evolving conditions at layers below such as physical changes (unplugging cables, connecting new cables, etc.) like automated railway switches to guide the messages down the right track.

6. There is one Administrator
Most applications that have any worth aren’t built and operated by one person, and if they are - you can bet that that person doesn’t understand the entire technology stack upon which their application sits on from the hardware, assembly, compilers, protocols, networking and infrastructure provided by other parties. This means that if something goes wrong with the application, there’s a chance that you or the original developer may not be capable of fixing it by yourself. It’s not even the fact that there may be multiple companies involved (for instance a web host, internet providers peering with each other, your company, etc.), but in each of those companies is multiple people each with completely different backgrounds and understanding of the technology at play. We as humans are all different, and it shouldn’t be assumed that one person understands everything or that one person should understand everything.
They say there isn’t a single person in the world that fully understands the process of making a pencil. The cedar, lacquer, graphit, ferrule, factice, pumice, wax, glue, and many other components all have different mining and refinement processes. There is no master mind. If we can’t even make a pencil by ourselves, can you really expect one person to fully understand and administrate the system that provides primitives for your application to execute and serve requests?
While there is some unreleated political arguments, the essay I, Pencil highlights that if we can’t even understand how to make a pencil, yet still make them - the unguided cooperation of many humans can take on tasks that are orders of magnitude more complex than a single person could possibly do on their own - including managing sophisticated communication and processing technologies.
The takeaway here is that there are many roles and dependencies that go into delivering your application. Also, when people are part of the operation, differences in a number of factors such as specialization, knowledge, the way they operate, and consistency of work all fluctuate. Even the same person on one day can be in a completely different mood and state of mind. Are they really the same administrator? The more straightforward you can make your application, the more reproducible you can make your deployments, the better. Use gold images and automated deployments when you can. A few good examples of this in practice are:
- VMware OVA files (deploy a virtual appliance, a VM with a fixed configuration - as if you purchased hardware to perform the task)
- Docker Images (deployed to a registry and pulled down by nodes as a container based on the image is scheduled to run on it)
- Kubernetes Deployment (a specification defining everything infrastructure requires to run a distributed application)
The special thing about these files is that they’re not just application packages, they’re deployment formats. They eliminate so much room for human error when deploying the application. When you upgrade the application, you don’t go in and start modifying the files in production then bring things back up… You redeploy from scratch each upgrade. The environment remains clean.
This is possibly the one fallacy that I see being solved in the near future - but for now, there’s still the gaps of domain knowledge between people that we need to worry about.
7. Transport Cost is Zero
Similar to fallacy #2 - Latency is zero, transporting data carries a price that’s paid with the currencies time and system resources. Network infrastructure has a cost, storage, servers, routers, switches, and load balances are only capable of handling so many requests. If you assume that the transport cost is zero, we have a tragedy of the commons scenario. This should be obvious to most people, however when building your application be sure you’re not caught up in the moment and pay consideration to data whenever it’s being moved around. There’s not too much to be said about this, other than you can have the smallest of messages and there’s still a cost of a resource that’s paid for it to be sent.
8. The Network is Homogeneous
Networks are duct taped together with different link types, protocols, and standards, yet it all works. There’s a lot of translation going on between these standards, yet it somehow (barely?… who am I kidding, it’s pretty robust for the problem it’s solving) works. We refer to the OSI model a lot in the networking world. The OSI model describes a stack of technology that drives networking, and for each higher numbered layer to succeed, it relies on all the properties and nuances of the layer below it.
The seven layers of the OSI model:
- Layer 1 - Physical Layer
- Layer 2 - Data Link Layer
- Layer 3 - Network Layer
- Layer 4 - Transport Layer
- Layer 5 - Session Layer
- Layer 6 - Presentation Layer
- Layer 7 - Application Layer
At the application level, you’ve got one layer to worry about! There are six more below you. These layers (1 - 4 and sometimes 5, 6) are the responsibility of the operations teams, the network service providers, the great minds that wrote the standards, the engineers that have implemented them, and the original researchers that provided foundational knowledge and systems. Let me tell you, it’s incredible how well this stuff works, but there’s also a lot of room for a something to malfunction and ruin your day, it happens. Sometimes a link will fail or be administratively switched. You might be running over fiber one minute, then DSL the next - but the messages have to keep flowing regardless of these entirely different physical mediums with different properties that get passed up the stack. It’s pretty standard nowadays to use fiber channel for storage networking, and ethernet for data networking - but it’s also pretty common to use ethernet for storage networking. The layers can be swapped out with other protocols at that same layer. This results in a lot of permutations of the underlying stack the application could possibly be running on.
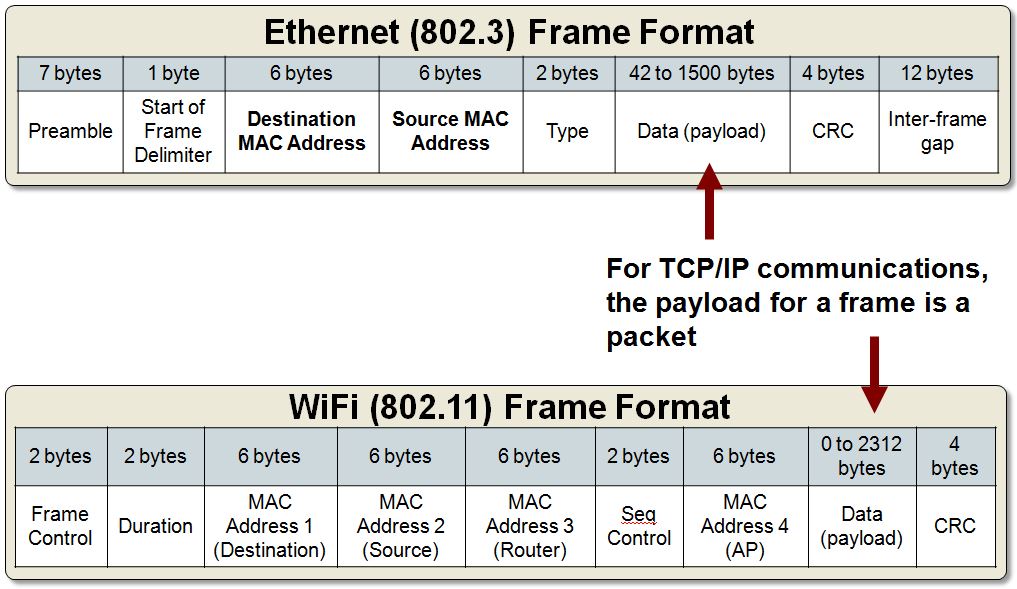
One last, soul-crushing bit of news, there’s also a lot of garbage implementations out there that may negatively impact the stack your application runs on. At the application level, the best thing you can focus on is using open standards, avoiding proprietary libraries for the entire messaging stack, and ensure interoperability. Be careful in what you send (stick to standards), and liberal in what you accept (accept a message if you can understand it, but it doesn’t follow the standard exactly). By doing this, your communications will remain robust under changing conditions of all the layers below it.
Conclusion
Nothing has changed in the past 20 years as far as these fallacies are concerned. They’ve stood the test of time and appear to be inherent properties of any distributed system. Use them as guidance and pay weight to each of them for each decision you make about your application communicates.
To go beyond addressing the necessity of addressing these fallacies - I recommend checking out my post about Antifragile Systems.